Analysis parts: Analysis intro, part2, part 3, part 4, part 5, part 6.
In this post, we’ll look at the view changes sub-protocol of the VR Revisited protocol and go over the questions that I had after reading the paper. I found the paper did not discuss a number of specific behaviours and situations which gave arise to a few doubts and questions. In following posts, we’ll look at how I used TLA+ to answer all these questions and test the validity of my thinking.
Before we begin…a note on timing
As we explore VR Revisited we will be focusing on edge cases. Some edge cases may seem unlikely but when you run complex systems at sufficient scale one-in-a-million events can occur everyday. Another way to look at the histories presented throughout this analysis is that what look like extremely unlikely timing issues are not so unlikely given the right configuration. For example, setting the primary timer expiry limit to 30 seconds is quite different to setting it to 1 ms. When set to 1 ms one could imagine all kinds of crazy combinations of view changes where a replica has a GC pause and wakes up hundreds of views behind.
If we were to dismiss unlikely timing issues, then we would have to start coaching human operators on the “right configurations”. Be careful not to set the expiry limit too low or you may lose data! So how low is too low?
If we want robust, correct distributed systems, then we need to take timing out of it and focus entirely on causality.
One final note: there are lots of diagrams, if you see a mistake please let me know. I have checked them but things can always be missed.
View changes
This post assumes you have read the View Changes section of the paper. It isn’t long or complex so I recommend doing so. I will summarise the rules here though. Before I do, I use the acronyms in this post:
SVC = StartViewChange message
DVC = DoViewChange message
SV = StartView message
f = a minority of replicas, which for 5 replicas equals 2. A majority is formed by at least f+1 replicas.
The way that view changes work in VR Revisited is that a replica can trigger a view change by advancing their view number and broadcasting a StartViewChange (SVC) message to all replicas. Each replica, on receiving this SVC, if it has a higher view number than its own, advances its view number and broadcasts its own SVC, causing a flood of SVC messages.

Fig 1. StartViewMessage (SVC) flood after r1 triggers a view change.
Once a replica has received f SVCs, it sends a DoViewChange (DVC) message to the primary of that view number. Primaries are calculated based on the view number, so in a 5 replica cluster, r2 would be the primary of views 2, 7 and 12 for example. Once a replica has received DVC messages from a majority (f+1), it becomes the new primary by broadcasting a StartView (SV) message.
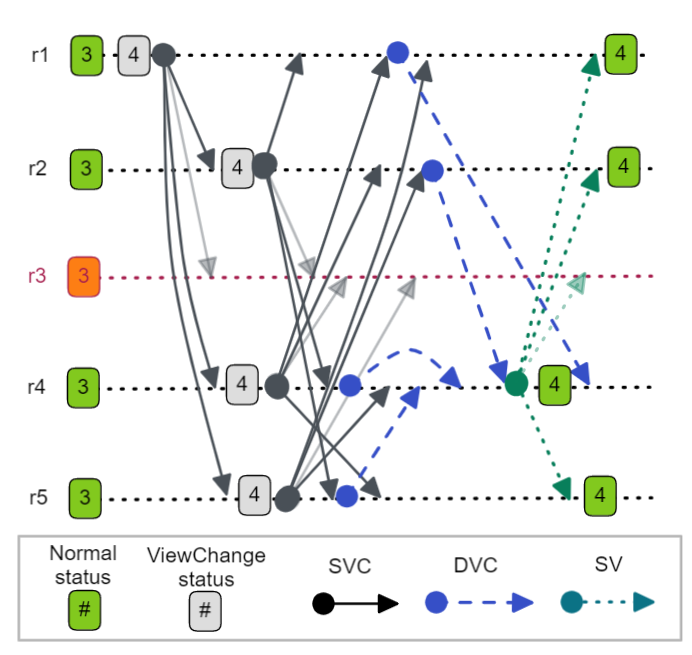
Fig 2. A complete view change with 5 replicas. All functioning replicas on receiving two StartViewChange messages with matching view numbers send a DoViewChange message to r4, the primary of view 4. Once r4 receives three DoViewChange messages it broadcasts a StartView message.
This is different to Raft in that the leader is determined by the view number - so leadership changes in a round-robin fashion. The view number acts like a Raft term, but who the leader is, is also encoded in that term.
View change rules (ignoring the client table in this post and without any optimizations):
A replica initiates a view change when either its timer expires (no messages were received from the primary for a time period) or it receives an SVC or DVC with a view number higher than it’s own.
To initiate a view change, a replica advances its view number and broadcasts an SVC message with its new view number.
Once a replica has received f SVC messages that match its view, it sends the primary of this view a DVC message containing its view number (v), log (l), last normal view (v’), op number (n) and commit number (k). If it is the primary, then it sends itself a DVC.
Once a replica has received f + 1 DVC messages, including one from itself, it sets its status to Normal, sets its view to that of the DVC messages and broadcasts an SV message with the view number (v), log (l), op number (n) and commit number (k).
The primary can now start accepting client requests and executing operations it hadn’t executed before.
When a replica receives an SV, it sets its view number, log and op number to those in the message and changes its status to Normal. If the replica has any uncommitted operations in its log, it sends the primary a PrepareOk message with the new op number and then executes all operations known to be committed that it hadn’t executed previously.
On reading the View Change section, many questions were whirling around my head. We’ll start with the simple questions that a short amount of reasoning about answered, then move on to the more complex questions.
Note we don’t care about the sending the entire log in messages at this point. The paper acknowledges this is a problem and includes optimizations. For now we’ll stick to the unoptimized version.
Question 1 - Are view numbers monotonic?
My first question was “are view numbers monotonic”? Monotonic here means that a replica will never set a view number to a lower value and basically ignores messages with lower view numbers. The paper does not restrict a replica from processing a DVC or SV message with a lower view number. The paper does describe:
“Replicas only process normal protocol messages containing a view-number that matches the view number they know. If the sender is behind, the receiver drops the message. If the sender is ahead, the replica performs a state transfer”.
Normal operations include only Prepare, PrepareOk and Commit messages. The paper also describes that only SVCs of the same view number are counted during a view change - but nothing about DVCs or SVs. Monotonicity of view numbers is required for correctness so I assumed it was a simple omission of the paper.
Unless otherwise stated, I assume that view numbers are monotonic.
Question 2 - How to count SVCs?
The paper states:
“When replica i receives STARTVIEWCHANGE messages for its view-number from f other replicas…”
This is a little vague. Does a replica only count SVCs that match its view number at the time of receipt or can it count SVCs that at the time didn’t match its view number, but now do?
If we have a three replica cluster and:
r1 with v=1 receives an SVC from r3 with v=2.
r1 increments its view number to v=2
r1 sends an SVC with v=2 to {r2, r3}
Has r1 met the threshold of f already? When it received the SVC from r3, it had a view number of v=1 and the message had v=2 so their view numbers didn’t match, but it did match after r1 incremented its view number.
So should r1:
Immediately send out a DVC to r2?
or wait to receive an SVC that matches its view at the time of message receipt? Basically wait for an SVC message with v=2 from r2.
The second option would cause a liveness issue because if r2 was down, then r1 would never receive an additional SVC with its view number. This would mean that even though a majority of replicas were available, the cluster would be unable to make progress.
So the answer is that all SVCs received that match the current view number are counted whether they matched at the moment of receipt or not.
Question 3 - Do view numbers just increment?
What does “advances its view-number” mean? Does it mean increment? It seems obvious that it does mean increment. But I could immediately see weird liveness issues with that so I was reluctant to believe it. Incrementing the view number on timer expiry was not controversial, the issue I had was incrementing the view on receiving an SVC or DVC with a higher view.
With Raft, if a node receives a message with a higher term, the node sets its term to match the term of the message - it does not increment its term. With Apache Kafka, if a node receives a message with a higher epoch, it assumes that epoch - it doesn’t increment its epoch. This has been the standard practice from my experience with multiple replication/consensus protocols. Also I could see some obvious liveness issues so it was difficult to accept that advance always meant increment.
There are two obvious situations where incrementing the view number on all three view change triggers causes liveness issues, one of those being very serious. The problem is that the increment-only approach assumes that all replicas start on the same view number.
Increment-only potential liveness issue 1 - One replica ahead of the rest
If a replica somehow gets too far ahead of a majority, it can cause various liveness issues.
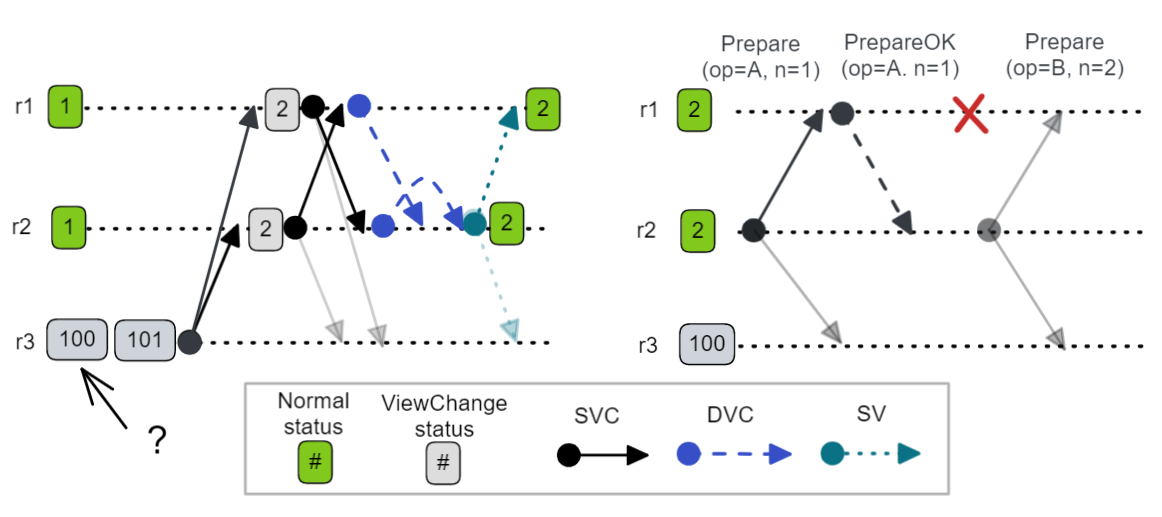
Fig 3. Increment-only approach with Left and Right liveness issue examples.
One replica (r3) has a view number that is far ahead, which causes mild to serious liveness issues. In the left example, it triggers a view change but is unable to join the view as the new view is still too low. This reduces the number of functioning replicas in the cluster.
In the right example r3 ignores Prepare messages because the view number is too low (and the replica will be in ViewChange status still). When r1 becomes unavailable, despite there being two available replicas, the cluster cannot make progress - as bad a liveness issue as it gets.
This makes it clear that increment-only must not allow any replica to move more than 1 view ahead of the majority. How that could happen or be prevented from happening is another question which we’ll address in the next question.
Increment-only liveness Issue 2 - One stale replica impacts view changes
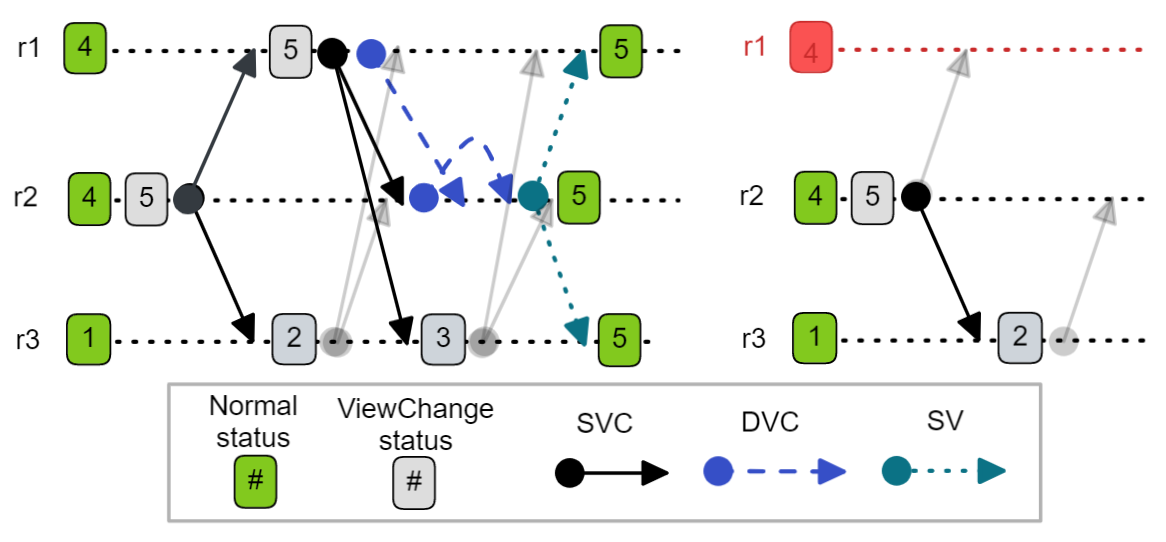
Fig 4. Two view changes with a stale view number. The left example can complete despite r3 being ignored, the right example shows a view change getting stuck.
On the left we see that r3 has a stale view of 1. Each SVC it receives causes it to increment its view number and broadcast a new SVC message that gets ignored by {r1, r2}. Ultimately it does join the new view on receiving the SV message. On the right-hand example, r1 is down causing r2 to start a view change for view 5. r3 increments its view to 2 but its SVC is ignored by r2. This raises the question of how to handle stuck view changes - see next question.
Increment-only mode seems to have some sub-optimal liveness properties and presents further questions like how to handle stuck view changes.
If “advances” were to mean increment the view on timer, but assume the message view number on receiving an SVC/DVC with a higher view, then we avoid that non-optimal behaviour. With assume-mode, r3 assumes the view number of an SVC or DVC message with a higher view number.
Assume-mode - One replica ahead of the rest causes no issues
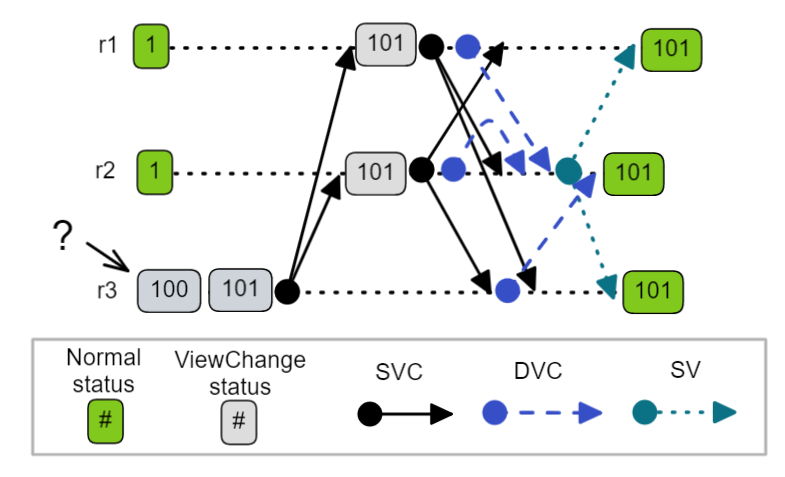
Fig 5. Assume-mode where timer expiry increments the view number but receiving an SVC or DVC message with a higher view causes the replica to assume the view of the message.
Assume-mode - One stale replica doesn’t block a view change
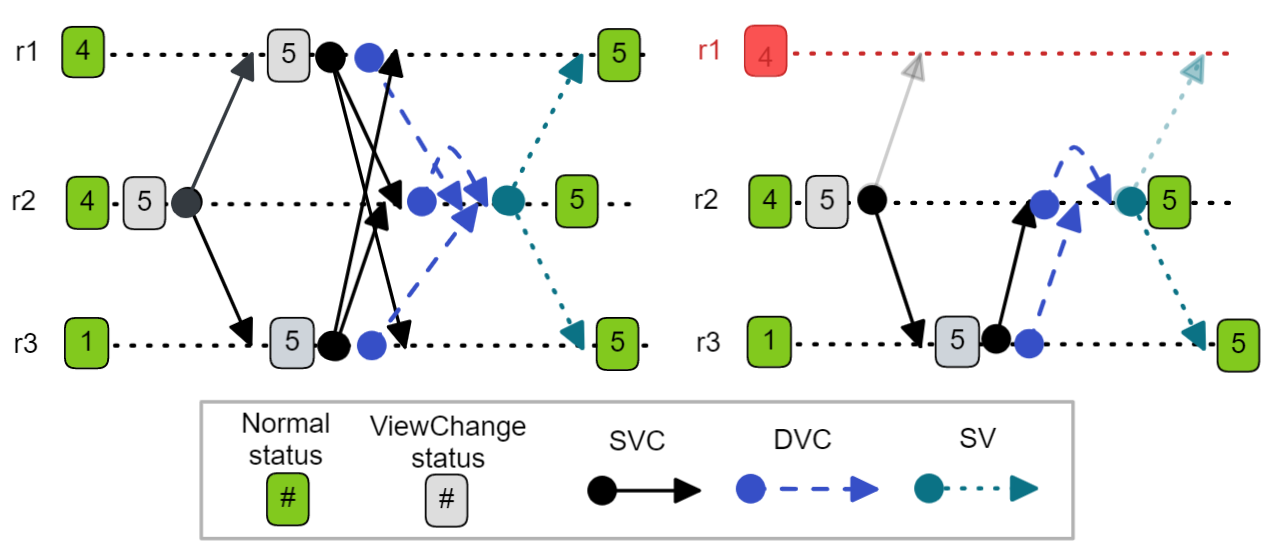
Fig 6. A stale replica is able to assume the new view immediately and therefore avoids the liveness issues associated with stale view numbers.
In the rest of this post I will refer to increment-mode and assume-mode, where assume-mode increments on the timer, but assumes the view number of an SVC or DVC with a higher view number.
Question 4 - How to handle stuck view changes?
My third question was about how stuck view changes are dealt with. The paper does not have any explicit discussion of this problem but it does say:
“the presentation ignores minor details having to do with filtering of duplicate messages and with re-sending of messages that appear to have been lost“.
What happens if r1 initiates a view change and broadcasts an SVC but never gets any corresponding SVCs from its peers? Should it just send the same messages again as the above sentence would indicate? But if the replica has a lower view number than its peers, those messages aren’t being lost they are being ignored so resending the messages in this case won’t help.
So we have two approaches that I will call Resend SVC and Start New View Change.
Stuck view change - Resend SVC strategy
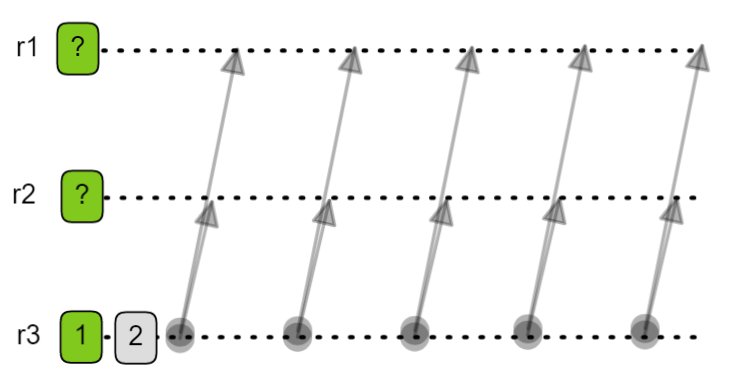
Fig 7. Resend SVC message strategy. r3 sends an SVC but receives no response so it waits for the timer to expire and resends the same view change for view 2 again. Repeats until it receives a response. But does it receive no response due to some network issue or because its view number is too low and it is being ignored?
This has a sub-optimal liveness issue where a single stale replica can cause a view change to take a long time to complete.
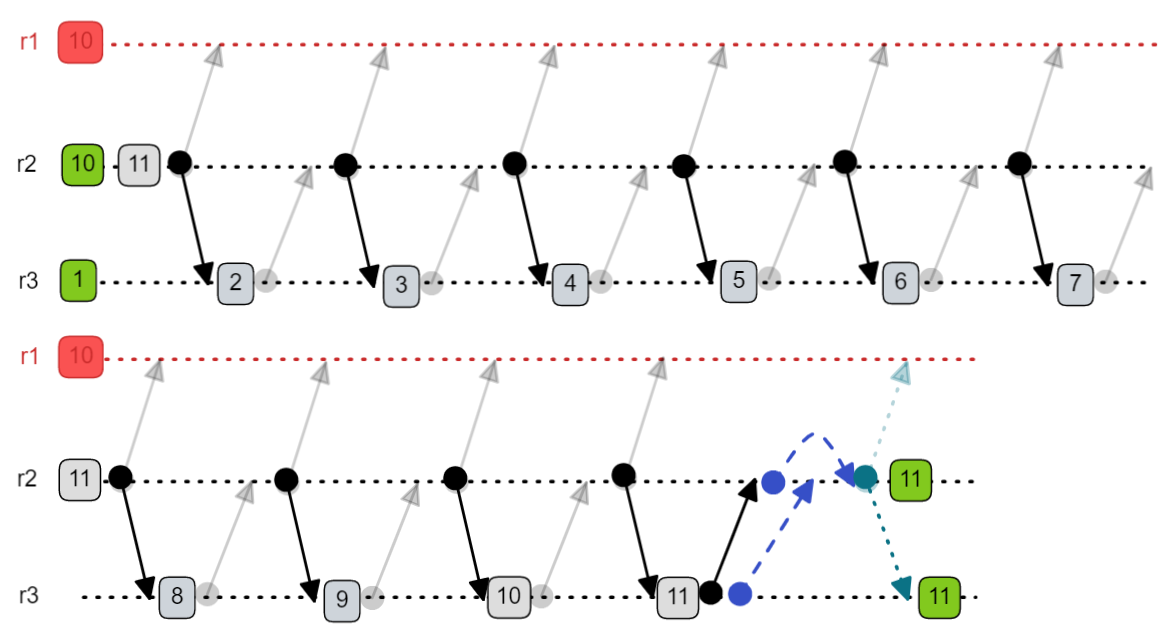
Fig 8. One stale replica holds back a view change because it is forced to increment its way through the view numbers until it catches up.
It’s worth noting here that VR Revisited has a mechanism called State Transfer that enables a replica to catch up if it has a stale view. However, state transfer only works if there is a functioning replica in the normal status. Looking at the above history, if r3 sends a GetState message to r2 with view 11, r2 would ignore it because r2 is in the ViewChange status. The only way for r3 to catch up in this scenario is for it to follow the history above where it increments its way to view 11.
Stuck view change - Start New View Change strategy
With this strategy the replica increments its view number again and broadcasts another set of SVCs. It keeps doing so until peers respond. This is the way Raft handles an election that times out midway through - it starts a new election.
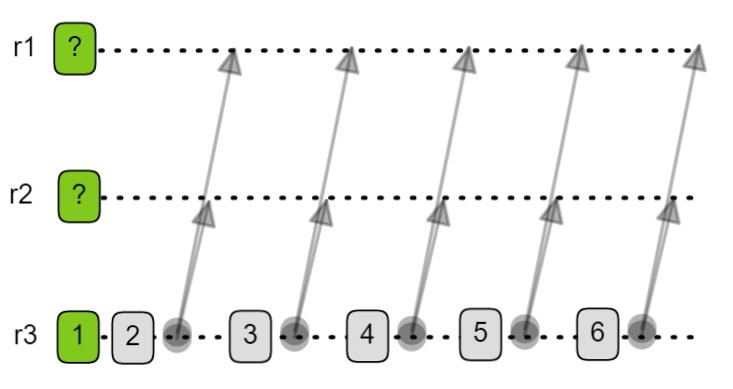
Fig 8. Start new view change strategy.
But if a replica uses the new view change strategy then it could end up a view number that was much higher than its peers and we know this is not an option with increment-mode. In fact, it’s worse than the histories we already described above. In the history below, r3 has been cut-off from {r1, r2} and has been attempting view changes throughput this period. It has now reached view 100 when the network issue gets resolved and its messages can get through to its peers.
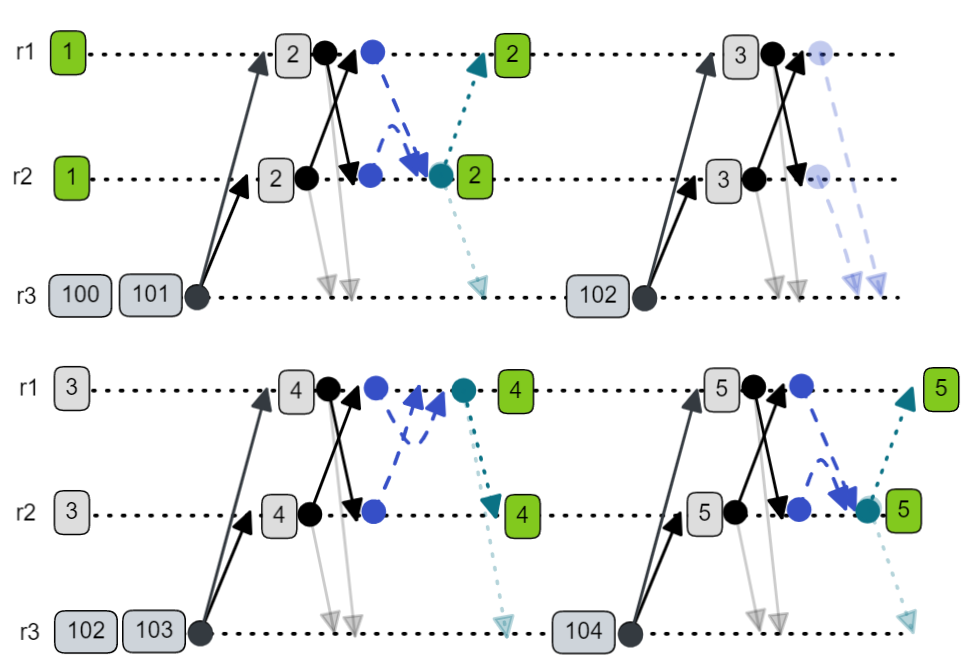
Fig 9. Combining increment-mode with the start new view change strategy for stuck view changes can create a disruptive non-functioning replica. This replica keeps starting new elections but cannot join the views as it ignores all messages from its peers with lower view numbers.
The only safe choice for increment mode is for a replica to resend the same SVC messages again when it gets no SVC messages in return. If we use assume-mode we can use either approach to handling stuck view changes.
Finally, there are view changes stuck in the DVC phase. What should a replica do if it sends a DVC to a replica but doesn’t receive a corresponding SV message? The simple answer here is that the replica should not try to resend the DVC as if the replica is down the view change will remain stuck until the primary comes back up. Instead the replica should start a new view change - there is no other choice if we care at all about liveness.
But is it safe with increment mode? Can it lead to a replica moving more than 1 view ahead of a majority? We’ll use an invariant in our TLA+ specification to verify if this can happen or not.
Question 5 - What to do if an SV message gets lost?
The paper has no StartViewResponse message - that is, the protocol does not have an explicit mechanism for a new primary to know that any given replica has received its SV. Does this matter?
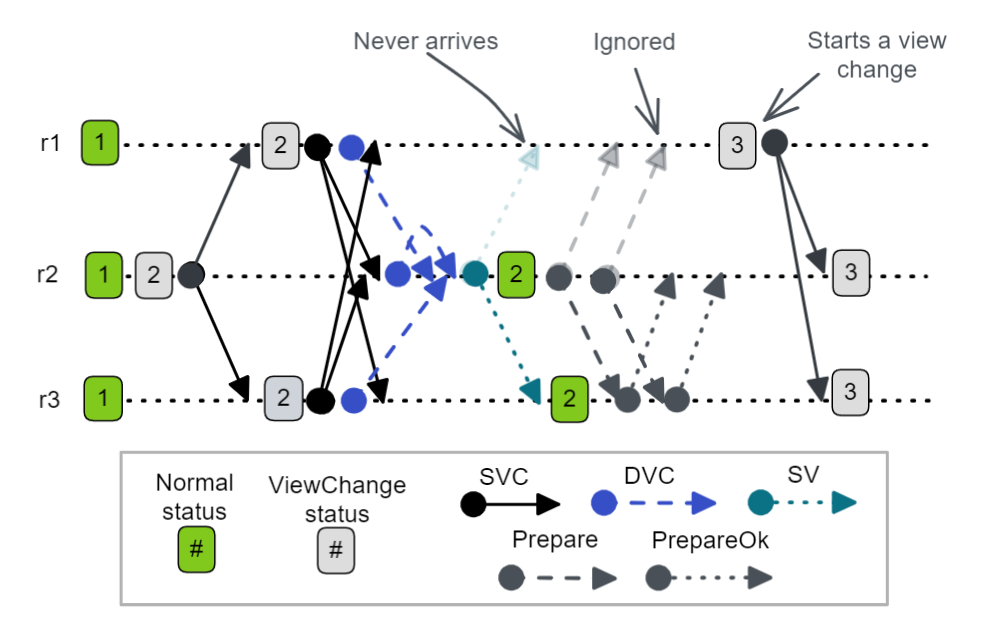
Fig 10. r1 never receives the SV from r2 and ignores subsequent Prepare messages, in the end it starts a new view change after not hearing from r2.
That is one history that is easy to foresee, whether or not further issues exist will be for something the model checker will have to find.
Question 6 - Can a replica receive DVCs with different view numbers?
The paper states that:
“When the new primary receives f + 1 DOVIEWCHANGE messages from different replicas (including itself), it sets its view-number to that in the messages”.
Is it possible for a replica to receive DVC messages with different view numbers where those view numbers both map to this same replica? For example in a three replica cluster, view 2 and 5 both map to r2. Is this possible for r2 to receive DVCs for both view 2 and view 5 during a single view change?
Question 7 - How to count DVCs?
The paper states:
“When the new primary receives f + 1 DOVIEWCHANGE messages from different replicas (including itself), it sets its view-number to that in the messages“.
Does the replica have to include itself? Seems unlikely, but the trouble with these protocols is that one misinterpretation can land you with a data loss bug, so I prefer to be careful.
The fact that the replica “sets its view-number to that in the messages” would indicate that there are valid examples where a replica receives DVCs that do not match its own view number and therefore hasn’t sent itself a DVC, else it wouldn’t need to state the above. One such example that I can think of is the below history.
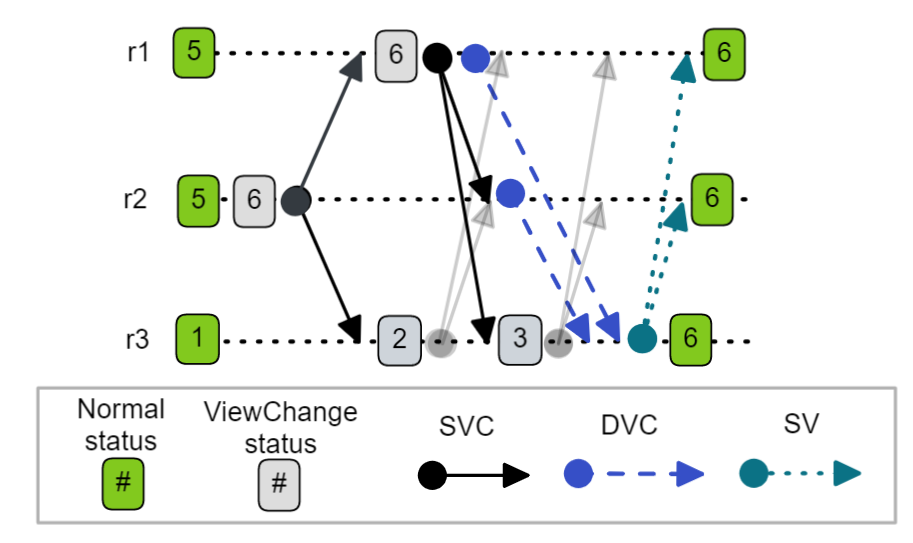
Fig 11. An increment-mode history where a replica accepts f+1 DVC messages from a different view to its own.
So the answer seems to be “no”, the replica does not have to include itself - that is, the replica can be in a view change and have a view number where it is not the primary - but still accept f + 1 DVCs of a different view and move to that view number and become the primary. This seems correct. Also note that this would not occur with assume-mode as it would already have set its view to that of the received DVCs.
But there is the niggling doubt about question 6 and receiving f+1 DVCs with different view numbers. If it did occur, how should we deal with it? Is it safe to count all DVC messages or should we only include the messages of the highest view? I would expect the latter is the case or else we violate the overlapping majority rule which would lead to data loss.
We’ll see if the model checker can confirm the existence of this issue.
Answering these questions with TLA+
While I wish the paper was as detailed as the Raft thesis, I can still get answers to all these questions using TLA+. I can also verify whether all my scenarios above are valid or not.
When I started out, I had most of these questions in my head and had an uneasy feeling as I proceeded to write a TLA+ specification. My gut told me that increment-mode was not the right way to implement VR so I strode ahead modelling assume-mode which felt more natural and proceeded to find a defect in the protocol.
However, I realised I had made a few too many interpretations of the paper to be sure my defect was valid - that I wasn’t just formally verifying a misinterpretation so I went back and started over, listing all the questions again and writing multiple TLA+ specifications. In the next part we’ll look at those specifications and see if we can answer all those questions definitively. Then later on we’ll look at the defects I found in my initial assume-mode specification as well as the state transfer and replica recovery sub-protocols.
Analysis parts: Analysis intro, part2, part 3, part 4, part 5, part 6.